User support
On this page we answer frequently asked questions (FAQs), and also give additional information for support, in case your question is not yet answered.
Frequently Asked Questions (FAQ)
Click on the questions to unfold the answers.
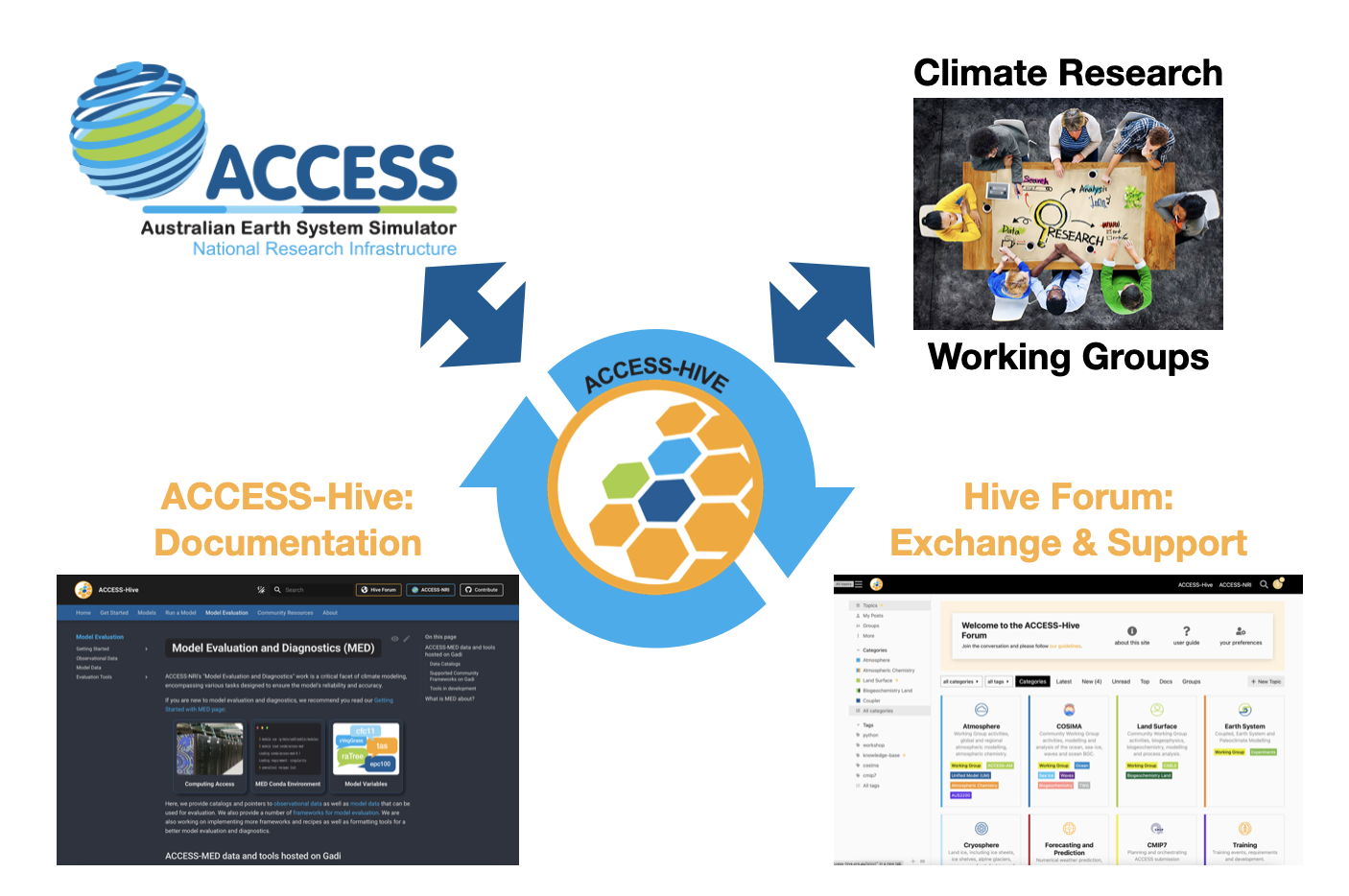
What is the difference between the ACCESS-Hive and the Hive Forum?
ACCESS-Hive is the open portal where ACCESS-NRI provides documentation for the ACCESS user community. The Hive Forum is the place where the ACCESS user community and its scientific working groups can exchange ideas and provide support.
What is the difference between model, model component, and model configuration?
A model component (sometimes referred to simply as component) is a codebase that is typically compiled into a single executable. It usually runs independently and communicates with other components via a coupler.
We refer to model as a general descriptive name for a particular combination of model components. For example, ACCESS-CM2 has 3 major model components: atmosphere (including land), ocean, and sea-ice. By contrast, ACCESS-OM2 has 2 major model components: ocean and sea-ice, with the atmospheric forcing provided by a data source.
A model configuration is a model (as described above) with a specific configuration (e.g. version, set of parameters) for each of its components.
What are Model Runs and Experiments?
A run is when a model configuration is executed, usually on an HPC system.
An experiment typically consists of one or multiple separate sequential runs, with each run picking up where the previous one finished.
So experiment and run can sometimes be used as synonyms, but at other times an experiment consists of many runs that are linked by passing model state from one run to the next.
How do model experiments and model evaluation work together?
Climate science - like all science - is based on the comparison of different models and hypothesis with observational data. We provide or support the frameworks to perform such comparisons as part of the model evaluation. The different model hypotheses, or more practically speaking model experiments, are created by executing different model configurations with different setups; for example by perturbing initial conditions or by adding new physical prescriptions to the models.
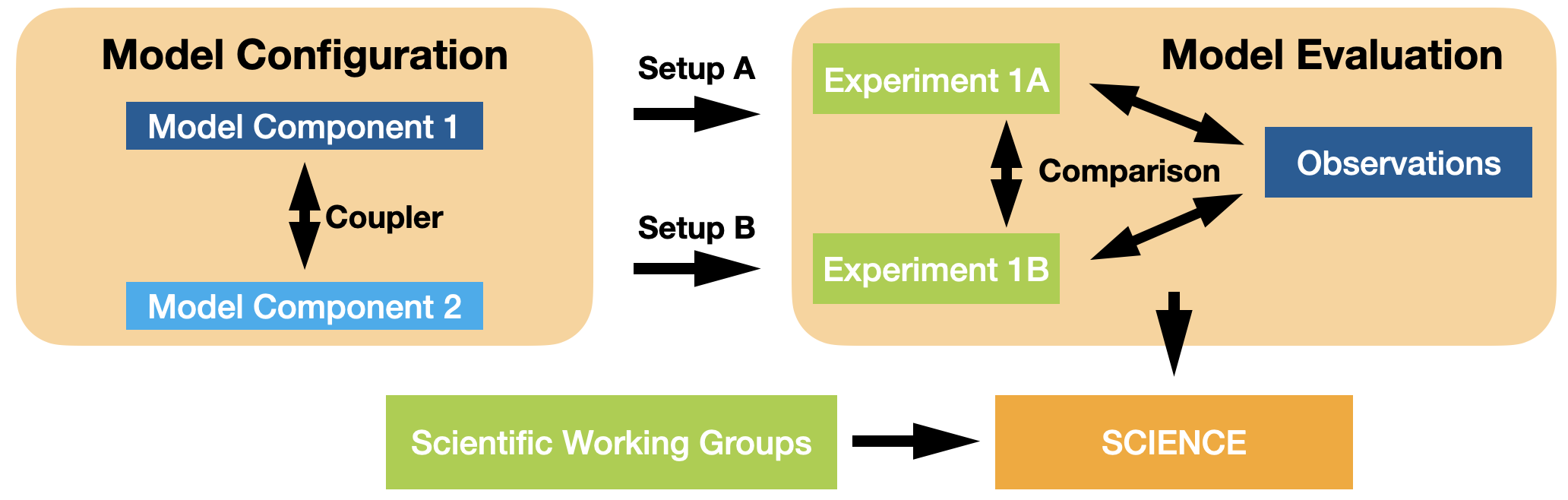
What is a control experiment? Why are they important?
A control experiment (sometimes also called a "control run") is an experiment that is designed to be used as a comparison against which perturbation experiments can be compared.
Control experiments are typically designed to represent some neutral climate state. For example, pre-industrial control experiments are designed to represent a modern climate state without significant anthropogenic climate forcing (global warming).
Control experiments are ideally well equilibrated, so that the model doesn't systematically change (often referred to as "drift").
Control experiments are important because it is an enormous saving in resources if one control experiment can be used by many researchers. It also means researchers can compare their perturbation experiments against not just the control run, but against each other.
What is a perturbation experiment?
A perturbation experiment is when a model configuration from a control experiment is altered in some way. The altered configuration is then run, restarting from a point in the control experiment.
The perturbation experiment is run in the same way as the control, each successive run using the state (restarts) from the previous run. The perturbation experiment can then be compared with the control experiment to see the effect of the perturbation.
Perturbation experiments are a very important way to try and understand complex earth systems, e.g. to isolate potential climate change signals and try and understand their effects.
Where can I find observational data and model data?
Both observational and model data is hosted by the National Computational Infrastructure (NCI) under different projects.
Go to our Observational Data section on the ACCESS-Hive to learn how to find and access observational data.
Go to our Model Data section on the ACCESS-Hive to learn how to find and access model data.
In both cases, you need to have access to the specific projects at NCI in order to read the data. For more information, check the First Steps page.
What is the difference between teams and working groups?
Throughout this documentation, we use the term teams to describe ACCESS-NRI's internal employees.
By contrast, we refer to working groups as the groups of the ACCESS community that work on specific ACCESS components, configurations or research topics. These working groups are formed by the scientific community itself, with ACCESS-NRI liaising between them.
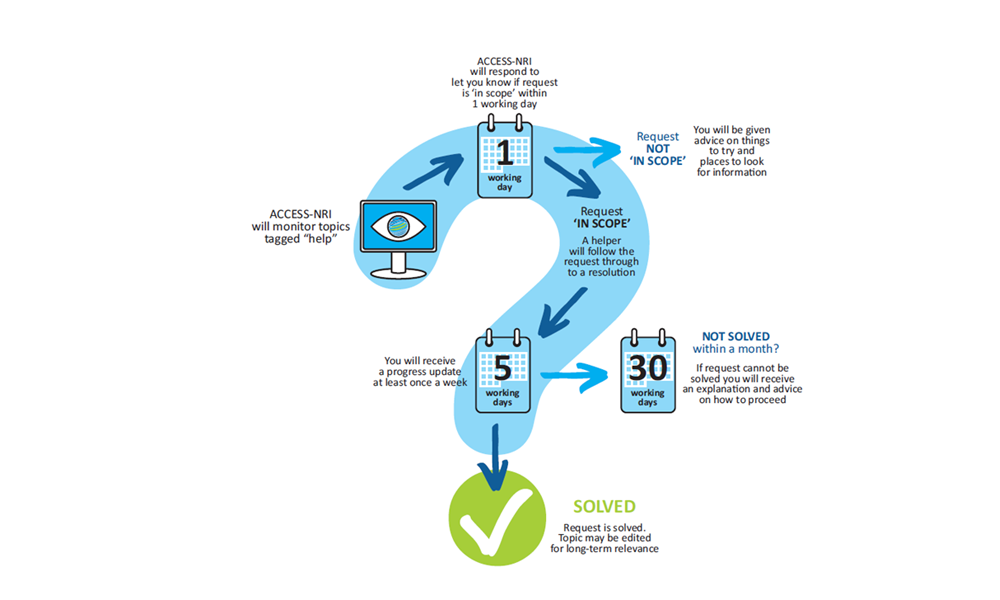
Still need help?
Consider asking for help on the ACCESS-Hive Forum. For content supported by ACCESS-NRI, a team member will provide support. For other content, a fellow member of the community might be able to help.
For further information on what assistance is available on the forum please visit the forum's Help and Support Page. There is also a Forum Support FAQ covering some of the more common questions you might have about what support is provided, how it is provided and what you can expect.